A robust vector retrieval system relies on a thoughtful selection of data sources that align with the system’s objectives. Different use cases demand different kinds and combinations of data.
If, for example, your organization runs a personalized movie recommendation system, you need data on customer preferences and viewing history. Whereas if you operate an automatic fraud detection system, your primary data source is transactional data.
In other words, data sources form the bedrock upon which your retrieval system stands. It’s important, therefore, to understand what different types and combinations of data are available, and what they make possible – both generally and in your specific instance. You need a data map.
An organization’s data is rarely uniform. Instead, the data landscape of any organization is a mosaic that can be characterized in terms of its velocity (ranging from stream to batch data), its modality / type (spanning structured to unstructured data), and its sources (originating from in-house systems and/or third-party providers).
Where your data falls along these three dimensions (velocity, modality, source) determines what you can do with it – that is, what use cases you can accommodate, and how you should configure your data retrieval stack to meet your objectives. In order to shape your data retrieval stack optimally, you need to build a mental model of your available data and understand its potential.
What you choose for your data and ML stack can make or break your whole product. Let’s look at an example of how your product strategy and use case can prescribe the kinds of decisions you make about your data and your ML Stack.
Pinterest used a product-led growth strategy that relied upon a curated feed of recommended “Pins”. Due to the highly viral nature of the product, this strategy allowed Pinterest to raise $564 million pre-revenue, ultimately growing to over 72.8 million users.
Pinterest uses diverse data types to improve the recommendation performance of its feed, including mechanisms to handle: - Structured data (e.g., user profiles): This includes well-defined attributes with specific formats. - Semi-structured data (e.g., event logs): These follow a general structure but may have varying fields or additional context. - Unstructured data (e.g., images): These are typically files without a fixed schema.
Below is an overview of the data & ML stack Pinterest uses to convert all this data (above) to product value.
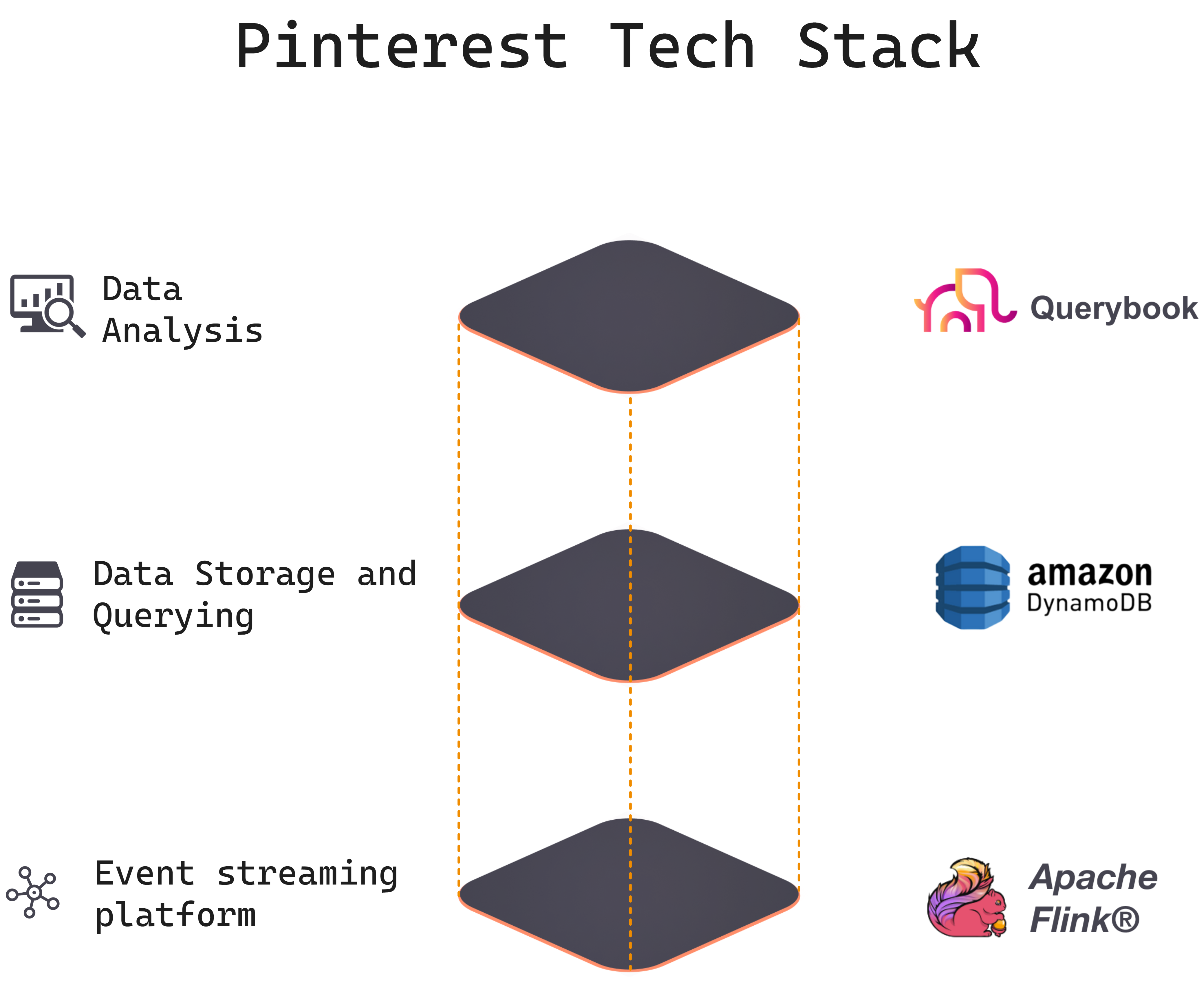
Event Streaming Platform:
Data Storage and Querying:
Data Analysis:
For precise details about Pinterest’s specific data types and components, check out their engineering blog.
Now let's dive into the details.
The choice of data processing velocity is pivotal in determining the kind of data retrieval and vector compute tasks you can perform. Different velocities offer distinct advantages and make different use cases possible.
Read more about different data velocities, here
Whether your data is structured, unstructured, or hybrid is crucial when evaluating data sources. The nature of the data source your vector retrieval system uses shapes how that data should be managed and processed.
Read more about how to manage different data types/modalities, here
So what does this all mean?
Read our conclusions and recommended next steps, here
Stay updated with VectorHub
Continue Reading