The choice of data processing velocity is pivotal in determining the kind of data retrieval and vector compute tasks you can perform. Different velocities offer distinct advantages and make different use cases possible. Here's a breakdown of the three primary velocity categories:
| Overview | Example |
|---|---|
| Technologies | Open source tools like Apache Spark, or proprietary batch pipeline systems in Google BigQuery, AWS Batch, or Snowflake. |
| Example Data | Historical sales data, customer records, monthly financial reports. |
| Properties | Batch processing involves processing data in fixed-size chunks or batches, typically scheduled at specific intervals (e.g., daily, weekly, or monthly). It can handle large volumes of data efficiently but lacks real-time responsiveness. For instance, a product recommendation system for an online store email newsletter might opt for batch updates. Updating recommendations once per week may suffice, given that the email is also sent once a week. |
| Data Formats | Common formats include CSV, Parquet, Avro, or any format that suits the specific data source. |
| Databases | Data storage systems like AWS S3 / Google Cloud Storage and document databases like MongoDB commonly store data that can be batch-processed for your retrieval system. |
| ETL-Able Systems | Systems like Magento for e-commerce or MailChimp for marketing are typical sources for batch accessed and processed data in your retrieval stack. |
| Overview | Example |
|---|---|
| Technologies | Apache Spark Structured Streaming, Apache Flink, Apache Beam. |
| Example Data | Social media posts, IoT sensor data, small-scale e-commerce transactions. |
| Properties | Micro-batch processing compromises batch and stream. It processes data in smaller, more frequent batches, allowing for near-real-time updates. It's suitable for use cases that balance real-time processing and resource efficiency. |
| Formats | Often similar to batch processing, with data structured in formats like JSON or Avro. |
| Overview | Example |
|---|---|
| Technologies | Apache Kafka, Apache Storm, Amazon Kinesis, hazelcast, bytewax, quix, streamkap, decodable. |
| Example Data | Social media feeds, stock market transactions, sensor readings, clickstream data, ad requests and responses. A credit card company aiming to detect fraudulent transactions in real-time benefits from streaming data. Real-time detection can prevent financial losses and protect customers from fraudulent activities. |
| Properties | Stream processing handles data in real-time, making it highly dynamic. It's designed to support immediate updates and changes, making it ideal for use cases that require up-to-the-second insights. |
| Formats | Data in stream processing is often in Protobuf, Avro, or other formats optimized for small footprint and fast serialization. |
| Databases | Real-time databases include Clickhouse, Redis, and RethinkDB. There are also in-memory databases, such as DuckDB and KuzuDB, which can be used to create real-time dashboards. However, depending on the deployment strategy chosen, these databases may lose the data once the application is terminated. |
Most systems deployed in production at scale combine stream and batch processing. This enables you to leverage the immediacy of real-time updates and the depth of historical data. But reconciling stream and batch processes in a single system introduces trade-off decisions – trade-off decisions you must make to keep your data consistent across systems and across time.
When choosing and configuring the data sources for a vector retrieval system, it’s important to consider tradeoffs between data velocity, complexity, and model size.
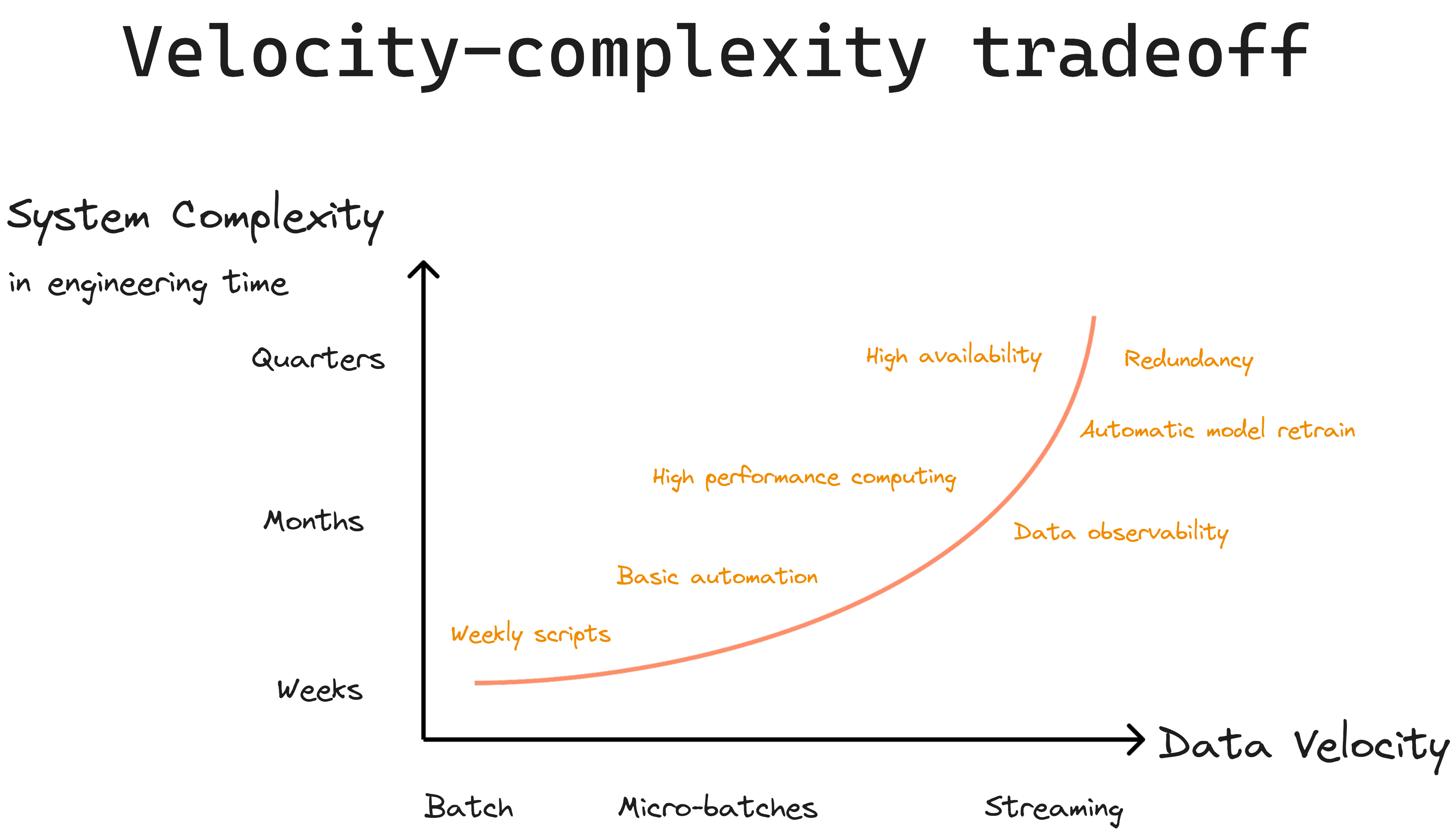
Different data sources impact how the data is then ingested and processed by your data & ML infrastructure. For a deep dive on how your choice of data sources affects the downstream systems in your information retrieval stack, see our article on Vector Compute. For the purposes of this discussion, you can think about data source choice in terms of a tradeoff between data velocity, retrieval quality, and engineering complexity.
| Aspect | Streaming Data | Batch Data | Hybrid Approaches |
|---|---|---|---|
| Model Complexity | Constraints on model complexity due to latency | Enables complex models, including large transformers | Balances streaming with batch retraining for analysis |
| Update Frequency | Real-time updates | Less frequent updates, suitable for asynchronous use | Combines streaming with batch for responsiveness and depth |
| Cost-effectiveness | Higher resource requirements | More cost-effective due to lower resource requirements | A balance of cost-effectiveness with real-time features |
| Data Consistency | Real-time updates, potential data consistency | Ensures data consistency | A balance of real-time and consistency |
| Timeliness & Relevance | Timely but may have lower content value | Timely and relevant | Timely and relevant |
How you configure your data sources to balance velocity and complexity ultimately manifests in the types of machine learning model architectures you use in your vector search system.
Example Architectures
Within a vector search system, there are three basic architecture types. These architectures balance velocity and complexity in different ways:
Choosing the right architecture depends on your goals:
Key Considerations
The trade-off between velocity and complexity is not the only important consideration in building your vector retrieval system. You also need to balance model size with response time.
As with velocity and complexity, balancing size with response time is consequential for the types of architectures you use in your vector search system.
Example Architectures
Besides the velocity-complexity and model size-response time tradeoffs above, there are some additional considerations pivotal to ensuring that you meet your vector retrieval system’s objectives:
In short, keeping these key considerations in mind while you balance velocity with complexity, and model size with response times, will help ensure that you configure your specific vector retrieval system optimally.
In the context of real-time data processing, the choice between Kappa and Lambda architectures involves evaluating trade-offs between velocity, complexity, and data value:
Kappa Architecture: Emphasizes real-time processing. Data is ingested as a continuous stream and processed in real-time to support immediate decisions. This approach is well-suited to use high-velocity cases, such as fraud detection systems in financial institutions.
Lambda Architecture: Combines batch and real-time processing. Data is ingested both as a stream and in batch mode. This approach offers the advantage of capturing high-velocity data while maintaining the value of historical data. It's suitable when there's a need for comprehensive insights that consider both real-time and historical data.
| Aspect | Kappa Architecture | Lambda Architecture |
|---|---|---|
| Real-Time Processing | Emphasizes real-time data processing. Data is ingested as a continuous stream and processed in real-time to support immediate decisions. | Combines batch and real-time processing. Data is ingested as a stream and batch, allowing for comprehensive analysis. |
| Simplicity | Offers a simpler architecture, with a single processing pipeline for real-time data. | Has a more complex architecture, with separate processing pipelines for real-time and batch data. |
| Scalability | Highly scalable for handling high-velocity data streams. Scales well with growing data loads. | Scalable but may involve more management due to the dual processing pipelines. |
| Latency | Provides low-latency processing, making it suitable for use cases that require immediate decisions, such as fraud detection. | Offers lower latency for real-time processing, but higher latency for batch processing. |
| Complex Analysis | May be less suitable for complex batch analysis. Real-time data is the primary focus. | Supports both real-time and batch processing, allowing for more comprehensive and complex analysis. |
| Data Consistency | May sacrifice some data consistency to prioritize real-time processing. | Ensures strong data consistency between real-time and batch views, making it suitable for data analytics and historical comparisons. |
| Use Cases | Ideal for use cases with high velocity, such as real-time monitoring, fraud detection, and sensor data processing. | Suitable for applications where historical data analysis, complex event processing, and reconciling real-time and batch views are required. |
Stay updated with VectorHub
Continue Reading