Evaluating Retrieval Augmented Generation using RAGAS
In our first article, we introduced RAG evaluation and its challenges, proposed an evaluation framework, and provided an overview of the various tools and approaches you can use to evaluate your RAG application. In this second of three articles, we leverage the knowledge and concepts we introduced in the first article, to walk you through our implementation of a RAG evaluation framework, RAGAS, which is based on Es et al.’s introductory paper. RAGAS aims to provide useful and actionable metrics, relying on as little annotated data as possible, making it a cheaper and faster way of evaluating your RAG pipeline than using LLMs.
SIE in the RAG stack
The Superlinked Inference Engine (SIE) is designed to sit inside a RAG pipeline as the inference and serving layer. We keep standard RAG framing here—retrieval and generation—because that matches how teams describe the stack and how RAGAS labels its metrics. Where it helps, we relate those metrics to operational concerns when you host and route models with SIE: inference latency, cost per evaluation run or query, model hosting and versioning, and ownership of models and IP that sit downstream of retrieval.
To set up our RAGAS evaluation framework, we apply ground truth—a concept we discussed in the first article. Some ground truth data—a golden set—provides a meaningful context for the metrics we use to evaluate our RAG pipeline’s generated responses. Our first step, therefore, in setting up RAGAS is creating an evaluation dataset, complete with questions, answers, and ground-truth data, that takes account of relevant context. Next, we’ll look more closely at evaluation metrics, and how to interpret them. Finally, we’ll look at how to use our evaluation dataset to assess a naive RAG pipeline on RAGAS metrics.
This article will take you through:
-
Creating a synthetic evaluation dataset
- a. evaluation dataset basics
- b. methods of generating questions
- c. tuning with answers
-
Metrics
- a. different RAGAS metrics
- b. ragas score
- c. RAGAS in action
-
Using an evaluation dataset to assess RAGAS metrics
Synthetic evaluation dataset
The basics of evaluation datasets
Golden or evaluation datasets are essential for assessing information retrieval systems. Typically, these datasets consist of triplets of queries, document ids, and relevance scores. In evaluation of RAG systems, the format is slightly adapted: queries are replaced by questions; document IDs by chunk_ids, which are linked with specific chunks of text as a reference for a ground truth; and relevance scores are replaced by context texts that serve to evaluate the answer generated by the system. We may also benefit from adding question complexity level; RAG systems may perform differently with questions of differing difficulty.
But generating numerous Question-Context-Answer samples by hand from reference data would be not only tedious but also inefficient. Furthermore, questions crafted by individuals may not achieve the complexity needed for effective evaluation, thereby diminishing the assessment’s accuracy. If manually creating a RAG evaluation dataset is not a feasible solution, what should you do instead? What’s an efficient and effective way of creating a RAG evaluation dataset?
In the full walkthrough (see the companion notebook), we compare question generation with T5, OpenAI, and RAGAS. RAGAS can produce a diverse baseline test set from your documents with relatively little code. Below is a preview of a RAGAS-generated baseline evaluation dataset and a zoomed-in row: question, contexts, and ground_truth are aligned so you can later compare pipeline answer and retrieved contexts against what RAGAS expects.
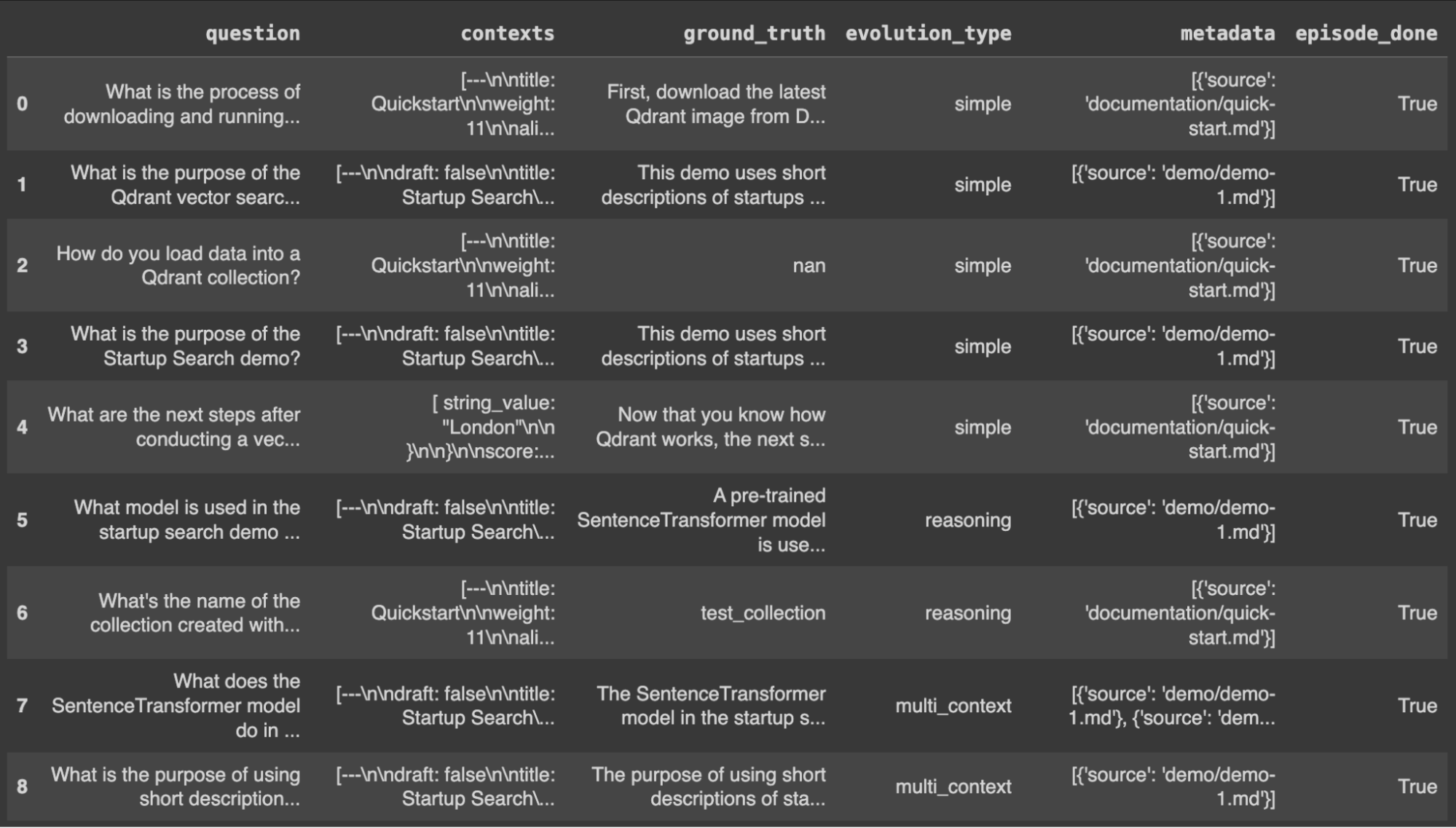
Preview of the RAGAS baseline evaluation dataset.
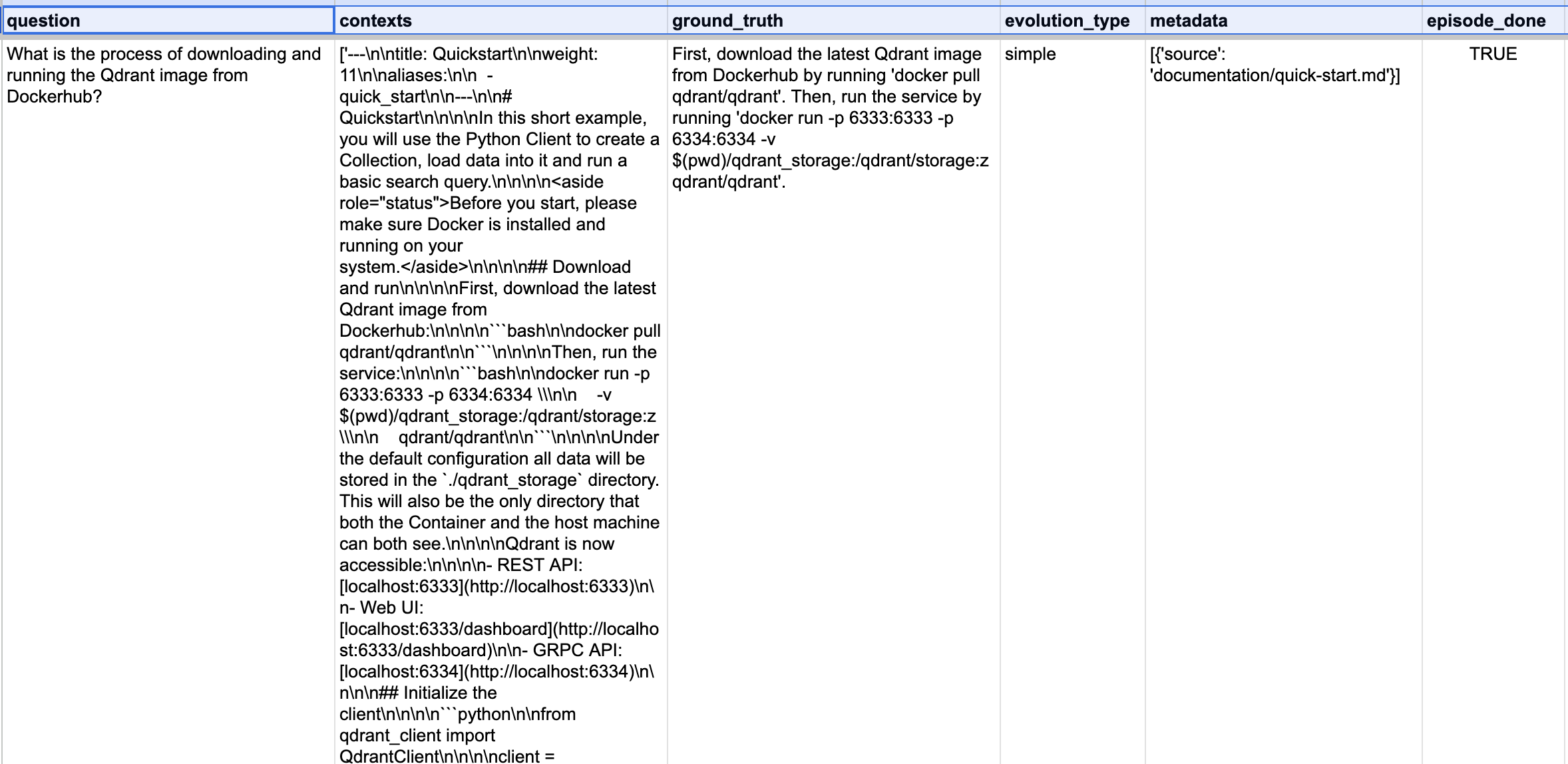
Sample row: question is generated from the listed contexts, with ground_truth used to evaluate the answer produced when the question is run through the RAG pipeline.
Metrics
As we enter our discussion of metrics, you may want to familiarize yourself with RAGAS’ core concepts.
RAGAS is focused on the retrieval and generation stages of RAG, and aims to provide end-to-end RAG system evaluation. This maps directly to how we think about SIE: RAGAS’ retrieval-oriented metrics reflect how well context is selected before inference; its generation-oriented metrics reflect the quality of the response produced by the model you serve—latency, cost, and hallucination risk all show up when those scores move.
RAGAS’ key evaluation metrics
-
Faithfulness
Measures factual consistency of the answer with the retrieved context. -
Answer relevancy
Measures alignment between the answer and the original question. -
Context recall
Measures how much of the ground truth is captured in retrieved context. -
Context precision
Measures whether relevant chunks are ranked highly.
The mean of these metrics forms the ragas score, a single evaluation metric summarizing system performance.
The ragas score
The ragas score reflects RAGAS’ focus on evaluating RAG retrieval and generation. It is the mean of faithfulness, answer relevancy, context recall, and context precision.
- Evaluating retrieval: context recall and context precision summarize whether the right evidence was retrieved and ranked well—directly relevant to vector DB and retriever tuning before context reaches your inference layer.
- Evaluating generation: faithfulness and answer relevancy summarize hallucination risk and whether the served model stayed on-question—central when SIE is hosting the generator.
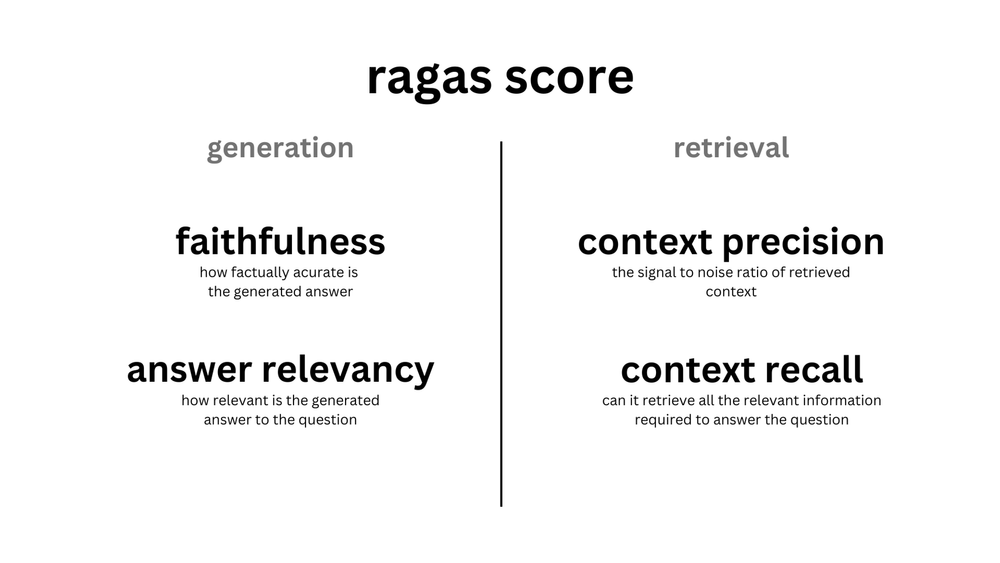
RAGAS metrics at a glance (from the original evaluation walkthrough).
RAGAS in action
Let’s build a naive RAG system on top of Qdrant’s documentation. We use the pre-compiled Hugging Face dataset (text and source) derived from that documentation.
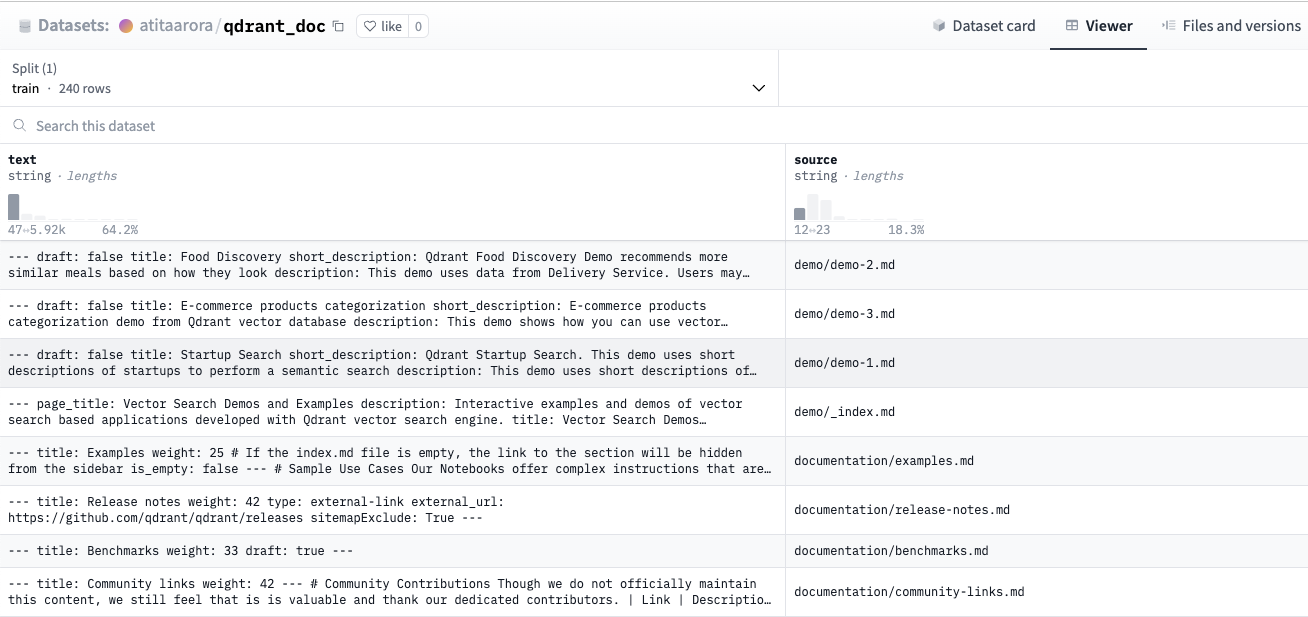
Preview of the source documentation dataset.
We process documents, chunk them, embed them, and store them in Qdrant.
We then retrieve relevant context and pass it into an LLM to generate responses.
SIE note: Chunk size, overlap, embedding model, and retriever settings all affect token volume and batching into your inference stack—changes that show up in RAGAS as retrieval metric shifts and, indirectly, in generation scores if the model sees noisier or thinner context.
Evaluating our RAG system using RAGAS
We leverage our baseline question–answer dataset to create an evaluation set (questions, answer, contexts, and ground_truth) from our RAG pipeline, and execute it using our evaluation methods.
We then evaluate performance using RAGAS metrics.
Sample RAGAS evaluation output for an early retrieval configuration.
Results and iteration
We observe that:
- Retrieval parameters impact context recall and precision
- Chunk size and overlap affect performance
- Embedding model choice matters
- Reranking improves results
These are all levers you can tune in a RAG pipeline. For SIE, each lever changes how much context you send to the generator, how often you call embedders or rerankers, and how heavy each inference step is—so RAGAS gives you a structured way to justify those serving costs against measured quality.
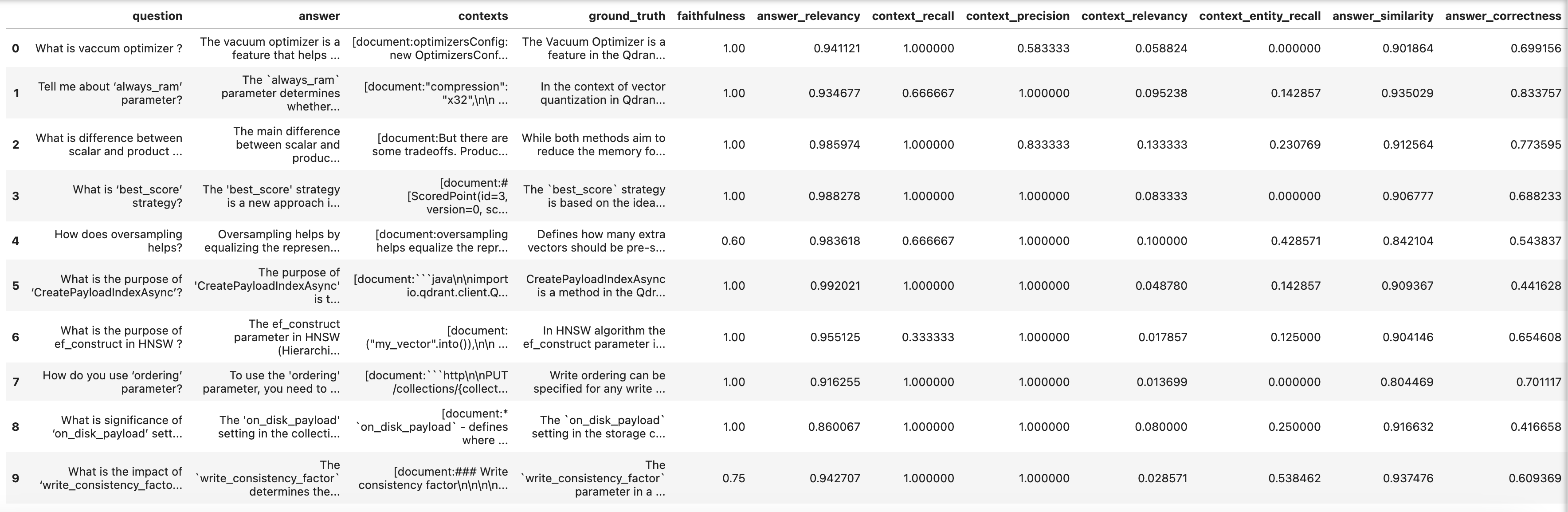
In the original experiment, widening the document retrieval window (number of chunks passed to the LLM) improved several metrics. Results with retrieval window 4:
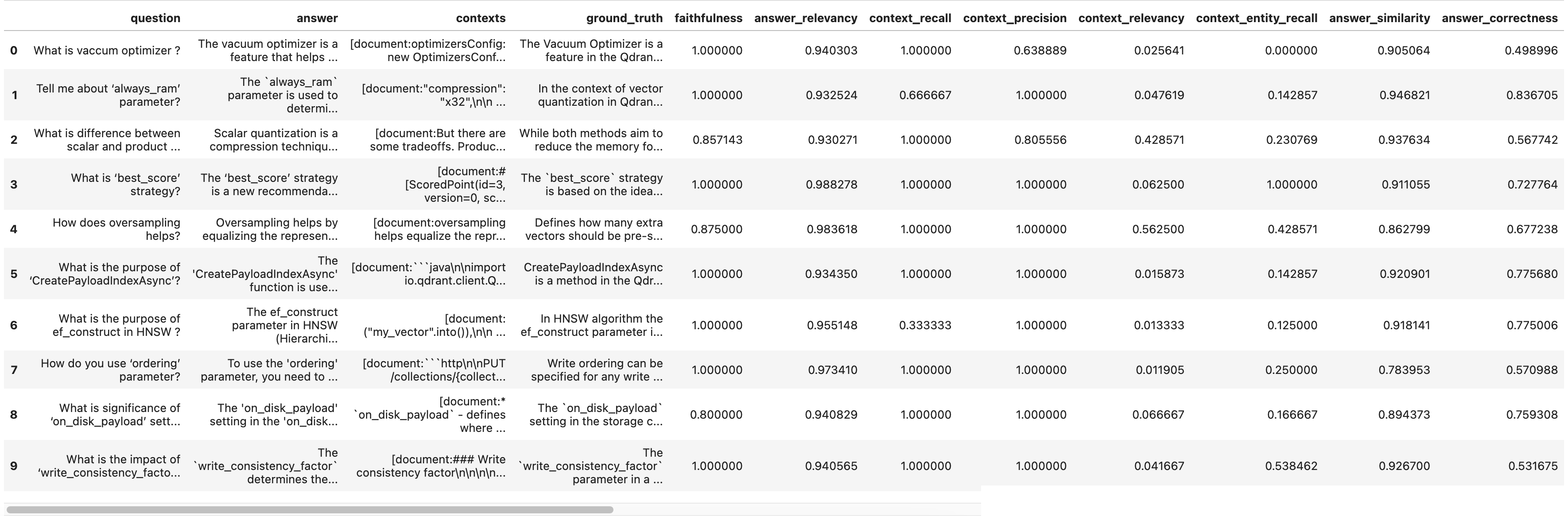
Results with retrieval window 5:
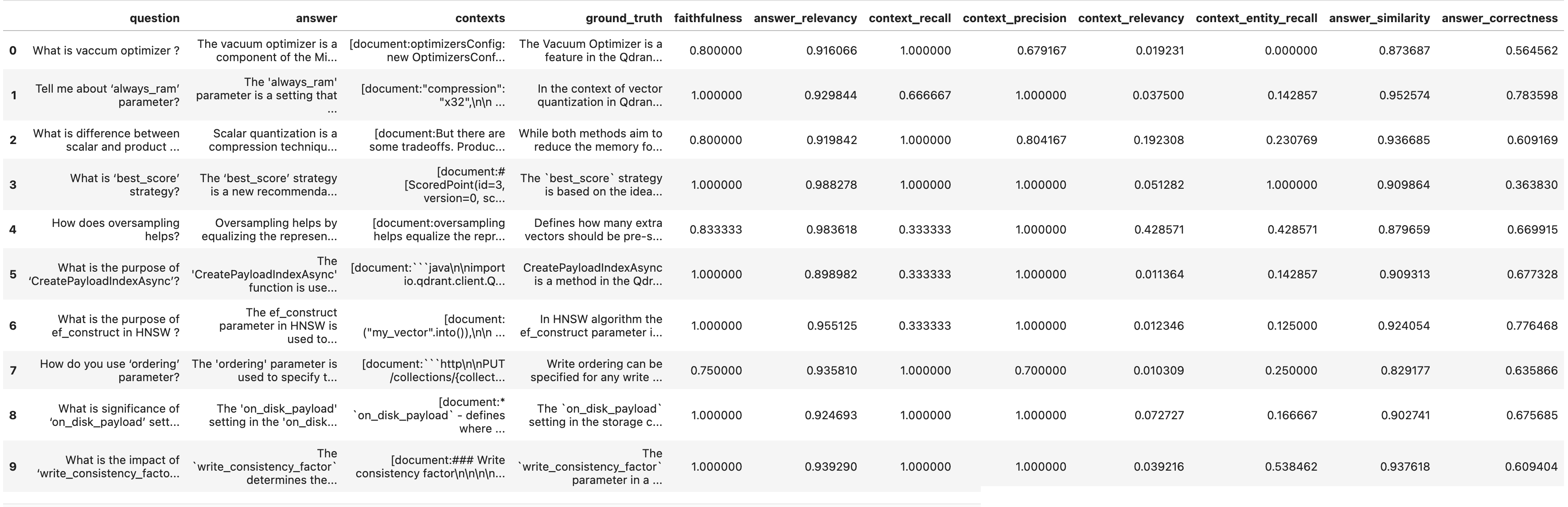
A side-by-side visualization of mean scores (RW_3, RW_4, RW_5) makes the trade-off visible: more context can help recall and correctness, but also increases tokens per request—affecting latency and cost under SIE.
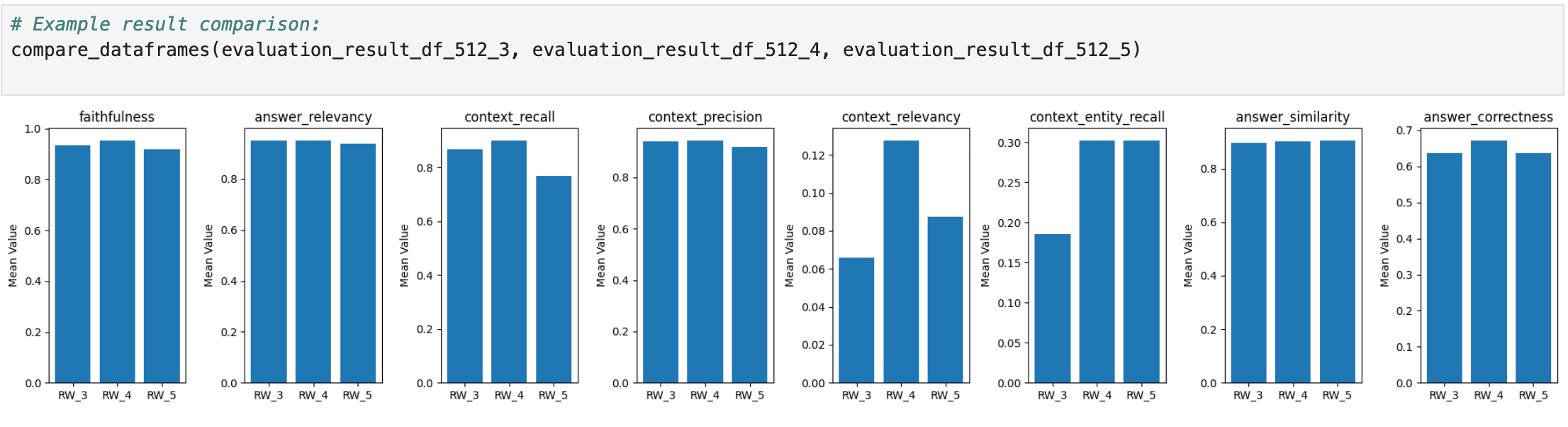
Retrieval window 3 vs 4 vs 5 (RW_3, RW_4, RW_5).
RAGAS also supports Aspect Critique for predefined dimensions such as harmfulness, maliciousness, coherence, correctness, and conciseness. Example output for retrieval window 4:
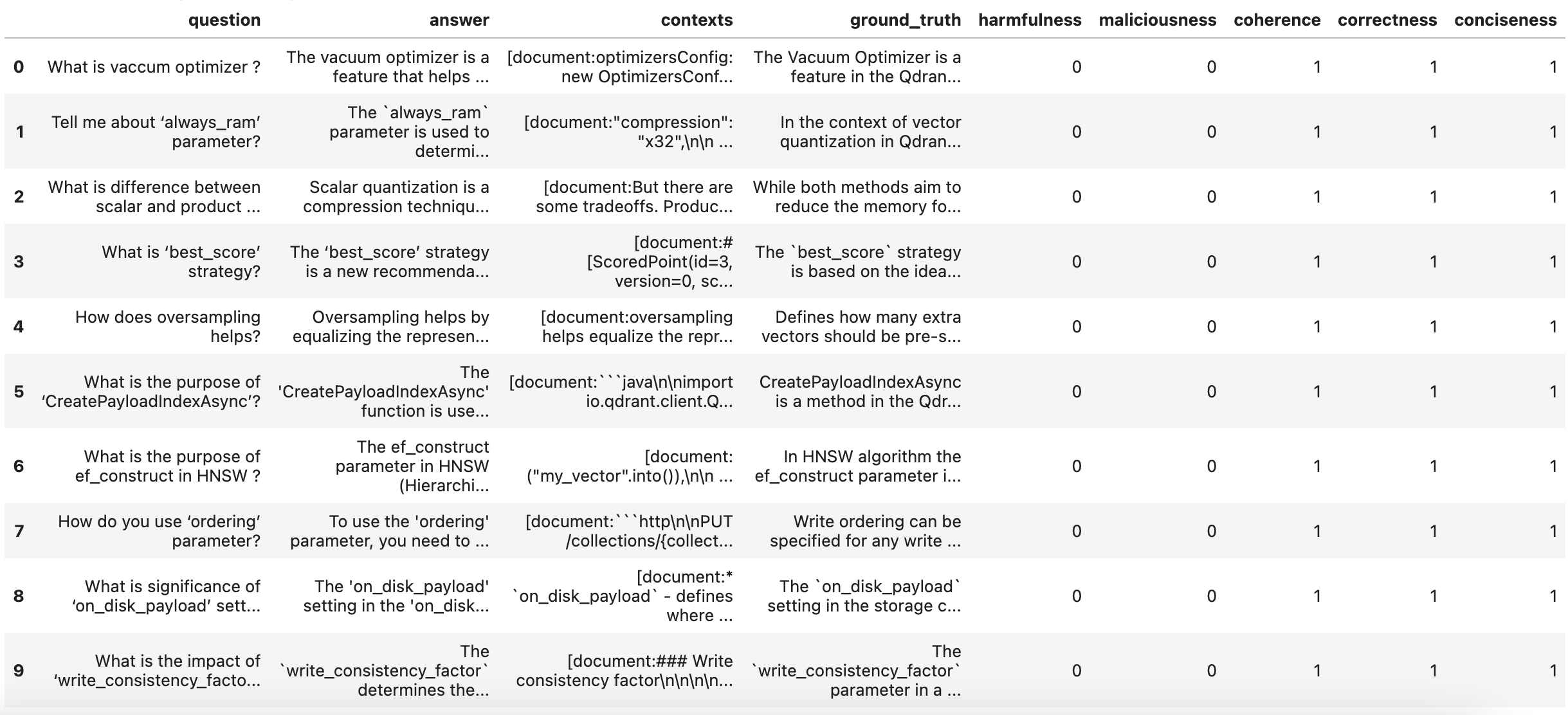
Aspect Critique scores for the RW_4 evaluation run.
In sum
We’ve walked through how to evaluate a RAG pipeline using RAGAS, from dataset creation through to metric interpretation and iterative improvement.
While the framework is RAG-focused, the same evaluation principles apply when SIE is the inference layer in the broader retrieval pipeline: improve retrieval and you change what the generator sees; improve generation and you change what users get for the same serving budget.
The full notebook and code for this RAGAS walkthrough are on GitHub: qdrant-rag-eval / workshop-rag-eval-qdrant-ragas.