It's become routine for large organizations to employ Retrieval-Augmented Generation when using LLMs on their data. By grounding LLM generation in existing data, RAG ensures increasingly robust resistance to hallucinations, adaptation to in-domain knowledge, and updatability. Still, RAG is typically understood as a temporary workaround, to be made redundant after the eventual advent of LLMs with improved context length and better intelligence.
After designing multiple RAG systems over the past year, I’ve come to believe they represent a radical transformation that will be here for years to come, more enduring than any LLM model they happen to integrate. RAG systems have the capacity to address the fundamental challenges of information retrieval, meeting the user and data where they're at. Effective RAG can take the best features of language models (adaptability, universal content translation) and moderate their shortcomings (misalignment, hallucinations, and lack of explainability), ingesting even heterogeneous, badly formatted data sources and contextualizing new knowledge on the fly.
The majority of vector search deployments today use RAG. It's become so integral that I recently not only find myself fine-tuning LLMs with RAG in mind, but also cofounded PleIAs to pre-train a new generation of LLMs for RAG end use and document-processing scenarios. RAG applications are not likely to be replaced by some disruptive revolution (e.g., long context) in LLMs. It's rather LLMs, as Yan et al. predicted, that are "likely to be the least durable component in the system" - swapped, combined, disabled.
RAG can be nothing less than a flexible, expert communication system - a feedback loop between LLMs and the data & user landscape of a company. RAG applications, therefore, should serve as the focal end point of fine-tuning, whatever LLM your RAG uses. Let's see how, in more detail, below.
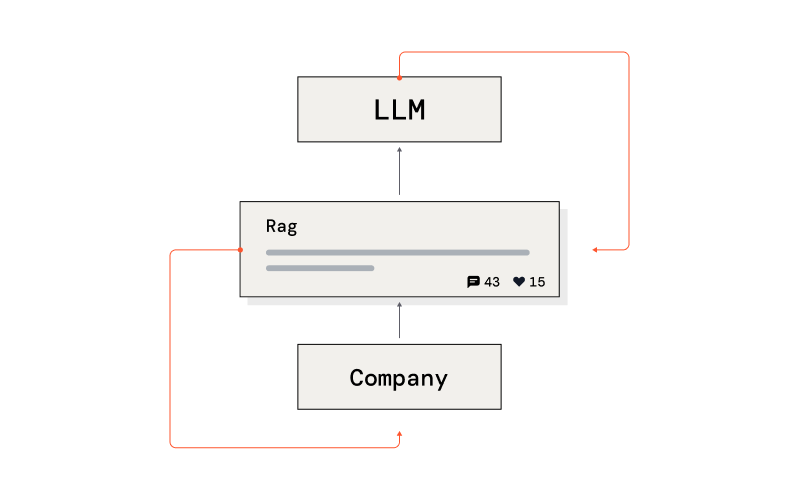
First, we'll look at how RAG addresses information retrieval challenges faced by but predating LLMs. We'll discuss why production RAG is dynamic, always solving the last mile problem (including evaluation) - customizing around LLMs to close the loop between data and users. We then go into more detail on info retrieval issues as data friction problems, and how we need to take a hybrid approach - deploying the best tools even if they're not new tools. We discuss the intricacies of specializing for production data, how you need bad data, synthetic data, and classifiers for pre-training, and the ins and outs of fine-tuning for RAG in production. Let's get started.
LLMs are extremely good and efficient at language transfer - rephrasing and reformulating an existing text in a new style, or for a different audience. Many models trained primarily in English can be adapted successfully on downstream tasks in other languages. This capacity also extends to other linguistic aspects: formal to informal, standards to dialects, generalist to specialized terminologies.
But LLMs are also limited. They are few doc-learners, largely conceived as “interpolated datasets” (holding in memory the collective knowledge of the Internet), and sharing the challenges of interpolated datasets. (Even the inaugural RAG system was still a form of interpolated dataset: a clever design associating a seq2seq model with a dense layer trained on Wikipedia (Lewis et al., 2020).) LLMs (like other interpolated datasets) are trained at a point in time on a finite set of data, and this creates problems. Problems that can to some degree be mitigated by RAG systems:
The default paradigm and basic conceptualization of RAG emerged almost immediately after the release of ChatGPT. Simon Willison’s “semantic search answers pattern” (January 2023) is one of the first systematic descriptions: search for texts in a semantic database, get the most relevant results, send this input to GPT-3 as inspiration. Following this basic strategy, RAG helps mitigate the limitations of few document learning by grounding an LLM on existing data at inference time.
But RAG doesn't solve LLM limitations once and for all. In production:
there's no one-size-fits-all RAG solution, as people working on production RAG today soon come to realize. Good applications are increasingly a lot of flows and arrows, anticipating a wide array of edge cases. There are simply too many breaking points - e.g., bad OCR, poor indexation, suboptimal tokenization, inconsistent document segmentation, unpredictable queries, etc. - to settle on one generic approach.
your solution to the last mile problem (indexing, retrieval, and generation) depends heavily on your use case: This won't be easily handled by LLMs, despite major AI actors' eagerness to create innovative panacea platforms. Probably the only actual moat in finding the right fit for your use case, corpus, and specific user target is in applied generative AI - i.e., in a specifically and dynamically tailored RAG system.
RAG evaluation is tricky: While you can use synthetic data to do preliminary evaluations and benchmarks for selecting and swapping models, the real challenge is evaluation in production of your system's different components, taking into account their level of specialization. Though we'd like to automate everything, including evaluation, here we continue to require qualitative human involvement.
These ongoing difficulties are at the same time challenges and opportunities for RAG applications qua communication systems - employing LLMs in a particular landscape of specific data and users. In a way, this has always been RAG's raison d'etre. As communication systems, RAG applications can perform better than even frontier LLMs alone, by taking advantage of a broad range of techniques, not all of them new, as we'll see below.
RAG is a new solution, and not the only one, to an issue that LLMs aimed to solve: information retrieval. But LLMs are not the only tools at our disposal. As part of a RAG comms system, our retrieval solutions need to be adaptive, incorporating the best performing parts of techniques, regardless of when they originated.
Expert systems and knowledge infrastructures have existed for decades, and dealt with the same data frictions RAG applications have to deal with today. On the data ingestion side, you still need to do additional work to fit new content to mandatory formats. On the query side, users don't act the way the search infrastructure expects.
Creators of the first expert systems in the 1960s expected that professionals would seamlessly access them. They wildly underestimated how much intermediation would be required. Though MEDLINE, for example, was designed for medical researchers and clinicians, and NASA/RECON, for aerospace engineers and scientists, most MEDLINE and NASA/RECON users through the 1970s were librarians and trained intermediaries, working on behalf of end users.
Expert info retrieval systems (1960s-70s) - intended vs. actual
| System | Intended user | Actual user | Training data |
|---|---|---|---|
| Medline | medical researchers, clinicians | librarians, trained intermediaries (complex search syntax - Boolean, MeSH, and UI) | medical journal citations |
| NASA/RECON | aerospace engineers, scientists | librarians, trained intermediaries | aerospace and engineering research papers, technical reports, scientific articles |
Like these early systems, the advent of LLMs and RAG promised a radical simplification of information retrieval - taking whatever content there is (via embedding models), and outputting (via LLMs) whatever the user wants. While it's true that embeddings are natively multilingual, theoretically resilient to synonyms, variations of language standards, and document artifacts, the radical promise made by LLMs and RAG was not fulfilled, and on the same two fronts as the earlier systems: understanding users, and understanding data.
LLM & RAG info retrieval (2017, 2020-now) - intended vs. actual
| System | Intended user query | Actual user query | Intended (training) data | Actual (use case) data |
|---|---|---|---|---|
| LLM, early RAG | full question queries | unstructured keyword queries | web, average 512 tokens / generic data | multi-page pdfs / specialized data |
It may seem obvious that knowing what your users are doing with your system is a necessary prerequisite to designing good information retrieval. But until recently, user behavior in the context of RAG had barely been discussed.
In general, RAG applications underestimate the inertia of user practices; users continue behaving the same way they did with older expert systems. I recently analyzed a set of internal user queries in a production chatbot, and was surprised to see that many users were submitting not questions but rather unstructured keywords. This practice works perfectly in a standard information retrieval system, but instruction-based LLM and embedding models are designed to be trained on question/answer pairs.
Inattention to user-design friction in LLMs and embedding models can result in poor performance, disappointed user expectations, tokenization that fails to adequately represent data structure, incongruity of input vs output lengths, and an overall lack of control over the system's purpose.
Like your users, your data won't necessarily comply with the constraints of LLMs and embedding models.
Context window, though it's gradually gotten longer, is still a limiting factor - the indexation of long texts continues to underperform. This results directly from a mismatch between pre-training data and data in production: the vast majority of Common Crawl texts are less than 512 tokens, whereas organizations routinely deal with multi-page PDFs.
Limited context windows require you to split or chunk your document, which is not trivial. Documents parts are not meant to be standalone units of content, and disambiguation requires some degree of cross-referencing. The biggest performance gain on my retrieval evaluation,especially on projects in the French public service sector, came from the systematic inclusion of title hierarchy (document > chapter > section, etc.); in long documents, general information on the topic is given at this scale, but not recalled in specific paragraphs.
Proper contextual support for original data is a concern in not just retrieval but also generation. Even powerful LLMs (frontier LLMs) are highly sensitive to document structure. Lack of proper segmentation or unusual structure will result in poor tokenization (typically, merging a document separator with a token), and a higher rate of omission and hallucination. With tables at least, a hacky (but verbose) fix is to recall the row name/column name couple before each entry.
Besides data context issues, there are also often issues with retrieval metrics.
Existing retrieval metrics, which rely on a binary relevance model, may not work well with embedding models, which rely instead on “similarity” to represent ingested data. Moreover, embedding models are trained on specific sets of documents and questions (typically bases like MS-Marco), and may not perform as well on specialized resources. Also, users' understanding of what data counts as similar may differ from what an embedding model represents as similar.
To meet users' expectations and do justice to our data sources, we have to do more than just blindly trust LLM embedding models or static RAG systems. We need a different, more flexible approach.
Even with recent advances (longer document limits, additional context enrichment), embedding models in RAG systems can barely compete with - and have to be supplemented by - classic information retrieval approaches, like BM25. This suggests a direction: recover the best performing info retrieval methods and indicators that can form part of a more flexible, high quality RAG comms system.
In practical terms:
In this time of LLMs, older information retrieval methods and indicators continue to hold a lot of unrealized value, especially now that it's possible to generate/extract many key data features at scale. Jo Kristian Bergum from Vespa, for example, has convincingly demonstrated how classic info retrieval evaluation design and metrics (precision at k, recall) can be effectively repurposed using emerging practices in AI, such as LLM-as-a-Judge - grounded on a small but scalable relevant dataset. Intensive data work that would have been available only to large scale organizations is now scalable with far fewer resources.
GOING HYBRID
- Indexation: traditional keyword matching + modern embedding-based similarity
- Searching: keyword-based search + vector search
- Evaluation: precision at k, recall + LLM-as-a-judge
Generative AI within a RAG communication system shouldn't be looking to replace the classic approaches of retrieval evaluation; it should instead reshape their logistics to take full advantage of them.
A proper RAG communication system should treat data no longer as a passive reference stock but rather a living entity - in two ways. Data should be:
A good RAG comm system includes: bad data + classifiers + synthetic data curation
As soon as you get even slightly beyond the proof-of-concept phase, your RAG system has to work with whatever data is available. To productionize, you have to become an expert on bad data.
Scaling is a bitter pill, and not just for LLMs: I worked in cultural heritage for years, and a library with millions of "bad", uncleaned OCR documents gets far more user interaction than one with a thousand perfectly (and expensively) cleaned and edited OCR texts. This also holds for large organizations. Their RAG has to work with legacy texts - i.e., PDFs, whereas LLMs are trained mostly on Common Crawl (web/html archives), not the digitization artifacts and advanced document structures of PDF documents. LLM trainers also don't have access to the bad data actually processed in production - from both users (minimal effort, "lazy" queries) and documents, either because of a poor retrieval system or they're restricted by data protection regulations, other internal organizational barriers.
But there are workarounds. The usual one is looking for placeholders, or generating them. Google (and probably other major AI providers), for example, have been seriously investing in data degradation techniques. Simple data processing heuristics (e.g., dropping cases, introducing noise) will do the job. My own experience has shown fine-tuning on existing bad data to be the most powerful way of preparing a RAG system for production use cases. (PleIAs' current generation of models is trained on a large corpus of diverse-format, non-HTML documents (especially PDF) with many digitization artifacts (OCR noise, bad segmentation).)
For processing bad (and good) data, we take advantage of LLM data processing power. But here too the best approach is using the best LLMs for production use cases, and not simply the newest or most popular decoders. The previous generation of encoders and encoder-decoders provide much better parameters / performance / robustness ratios for many data tasks than GPT-4, Llama, or Mistral. I increasingly build RAG systems with classifiers or "reformulators" that can reliably handle:
For automated query rerouting, query expansion, and text segmentation, using an LLM is overkill; it results in performance lag and degradation. Once properly re-trained, encoder models yield results comparable to an LLM's, are very fast, not expensive to host, and better fitted to the overall purpose of classification. In addition, encoders don't require structured generation, regex, or data constraints - the data design is already built-in.
In the months to come, I anticipate a lot of research on pre-generation of system input and output from a model, rather than generation at inference time. As RAG systems scale, pre-generation (solving and storing query answers beforehand) provides significant economies of scale, preferably when you have a general grasp of what queries or topics users ask frequently. Most queries follow a 80-20 rule (80% of questions are about 20% of topics); once a question is solved and stored, you don't need to regenerate it, saving computational resources.
It's also possible to expand the original dataset to include the types of queries your users are likely to write. At which point, a RAG dataset starts to look more and more like an instruction dataset, structured around a couple of answers and (generated) queries, and therefore also becomes a resource for fine-tuning and reconfiguring the model's behavior.
In a RAG context, fine-tuning is neither an alternative nor simply a good supplement to content retrieval: LLM memory is inconsistent, even more so when it relies on LoRA (Low-Rank Adaptation) rather than pretraining. Fine-tuning is better conceived as a method for enhancing communication, by tweaking the word probabilities of the base model in a specific direction:
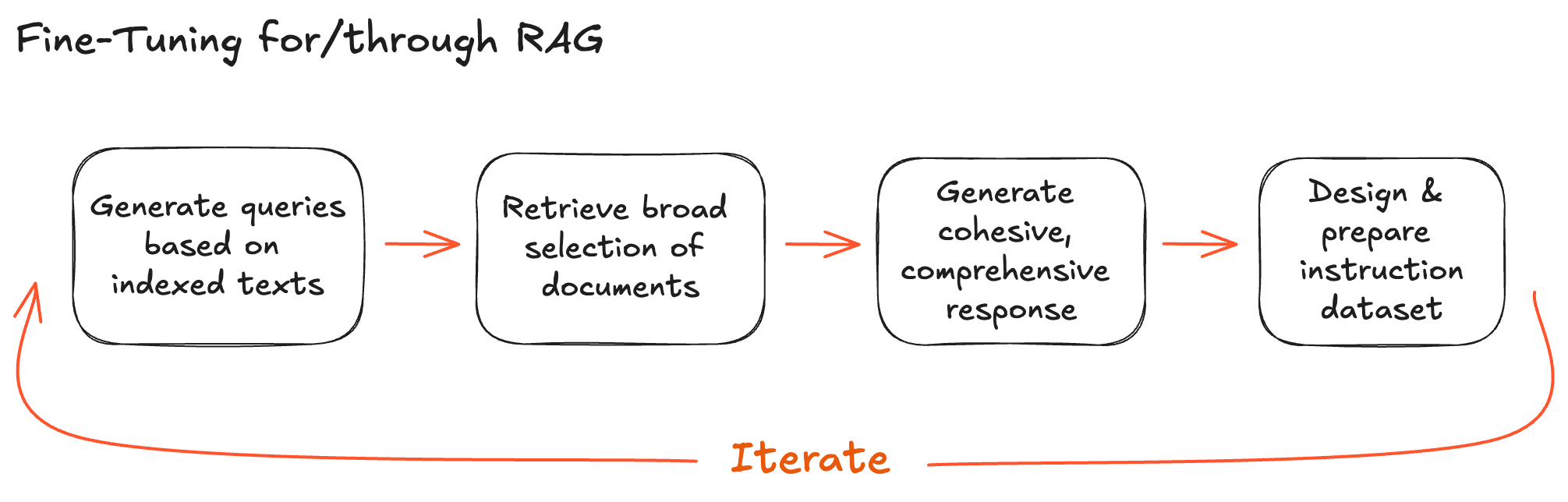
Fine-tuning has to come later in the cycle of development. In my experience, good instruction datasets need to be designed not only with RAG in mind but through (i.e., using) RAG. My standard protocol for RAG-based fine-tuning goes like this:
A good fine-tuning dataset, though it requires a significant amount of careful manual tweaking, does not require a lot of examples. Most of my projects are in the 1,000-4,000 instructions range, sufficiently large to warrant text generation, sufficiently small to still be mostly an opinionated product. The instruction dataset is in many ways a miniature version of the entire RAG communication system. It needs to approximate in format and style the future queries your users will send, the existing and future documents you will use for grounding, and the expected output. In short, you are designing a translation process and - through the instructions - providing it with all the use cases where the translation went right.
Preparation of the instruction dataset and base model improvement should be your main focus; these have the most impact on performance. I don't spend much time optimizing the training design beyond a few hyperparameters (learning rate, batch size, etc.). I've also generally stopped looking into preference fine-tuning (like DPO); the time spent was not worth the very few improvement points.
While it's far less common, you can also apply this approach (i.e., fine-tuning your instruction dataset using RAG-generated synthetic data) to embedding models. Synthetic data makes it considerably easier to create an instruction dataset that maps the expected format of the similarity dataset (including queries and “hard negatives”). Fine-tuning your embedding models with synthetic data will confer the same benefits as LLM fine-tuning: cost savings (a much smaller model that demonstrates the same level of performance as a big one) and appropriateness, by bringing the “similarity” score closer to the expectations of your retrieval system.
LLMs are built for general use, rather than specifically designed for your use cases. Prompt engineering on them can only take you so far. The primary objective of fine-tuning a RAG system is to improve its ability to generate documents that are accurate, relevant, and reliable in terms of your specific use case/s.
Robust RAG document synthesis requires:
Our RAG projects at PleIAs were conceived in the context of severe constraints on verifiability (public sector, large legacy privacy companies). We took inspiration from Wikipedia, who faced similar constraints: because texts can't be attributed to individual authors who take responsibility for their publication and trustworthiness, accuracy stems mostly from verifiability - associating individual statements with exact passages in secondary sources. While frontier LLMs can achieve high quality performance without fine-tuning (and this was actually our first approach), we have opted for a RAG fine-tuning approach to avoid the limitations of frontier LLMs:
The most straightforward way to measure accuracy is comparing the model output with the original documents. This works best when you're simply checking a system you've set up for attributing specific statements to their respective documents using generated references. You can use LLM-as-a-judge, or, if you provide actual quotes, a direct comparison with the original text (i.e., via a “text alignment” algorithm).
On a long term, using generalist models like GPT-3.5/4 in your RAG system creates a user alignment gap. This gap is even more pronounced if (like me) you’re working in a language other than English - ChatGPT creates strange ways of saying things that no one speaking standard French would use.
In my experience, fine-tuning is the most effective method of reshaping the style and overall method of communication of an LLM. A few months ago, I released MonadGPT, an instruction model trained on 17th century English. Fitting the communication scheme took the most time - i.e., fine-tuning an LLM on a couple of answers from historical texts, and generated questions in contemporary English, so that users aren't expected to mimic 17th century English, or the style of any of the document resources.
When fine-tuning, you should aim for the following kind of style alignment:
The best way to assess style (and related) frictions is probably to simply collect feedback from your users. You don’t need anything fancy: an open-ended comment section somewhere (and green/red buttons) works just fine.
Now, in mid-2024, we're probably at a crossroads. A major breakthrough in LLM research (e.g., Q*, Monte Carlo Tree Search, diffusion models, state space models, etc.) that shifts the focus back to model architecture is not impossible. But LLMs may be ceding center state to larger, more complex, production RAG systems that orchestrate and employ LLMs as embedding models and classifiers. (Once multiple decoder models are scalable for production, RAG will integrate them as well.)
RAG's ability to specialize through model orchestration positions it to solve multiple complex problems that plague LLMs in production:
We're in the early stages of a new generation of LLMs and SLMs made for RAG and RAG-associated tasks. CommandR (from Cohere), for example, is designed with enhanced support for source quotation and document interaction. Microsoft's smallest Phi-3 variant (a local LLM used in RAG setups) is optimized for contexts where knowledge and memory are separated from reasoning capacity, as they are in RAG. In addition, RAG datasets are growing. Even for specialized applications with a limited audience, there are strong incentives to expand the range of indexed context to cover more use cases. With RAG improvements in retrieval quality and efficiency, content that's less directly relevant (e.g., generalist newspaper articles, or even parts of Common Crawl) is increasingly usable.
With improving ROI on customization (increasingly the domain not of behemoth AI but rather mid-size organizations with advanced data expertise), and diminishing returns on gigantic, panacea models, RAG comm systems designed with more attention to production imperatives may well come to eclipse LLMs in importance.
Stay updated with VectorHub
Continue Reading