Keeping your retrieval stack up to date with Change Data Capture
Contributors
Was this helpful?
Publication Date: November 27, 2023||
Data Modality
Understanding the different Data Modality / Types
Whether your data is structured, unstructured, or hybrid is crucial when evaluating data sources. The nature of the data source your vector retrieval system uses shapes how that data should be managed and processed.
Unstructured Data
Unstructured data encompasses a wide variety of information that doesn't adhere to a fixed structure or definition. This data type is often characterized by its raw, unordered, and noisy nature. Examples of unstructured data include natural language text, image, audio, and video data. Let's take a closer look at each type:
Text Data
Example Data: Social media posts, news articles, chat transcripts, product reviews.
When building information retrieval systems, choosing the right dataset for evaluation is key. As a rule, you should always do this using your company’s or product’s own data.
However, there are also instances when using a 3rd party dataset for evaluation is possible, preferable, or even the only option. Most commonly, this occurs when:
Your own data quality or volume is insufficient for robust evaluation.
You want to standardize your evaluation results by running your system against a standardized evaluation dataset available in the market.
Let’s look at a couple of evaluation dataset examples for language models:
GLUE (General Language Understanding Evaluation) and SuperGLUE (Super General Language Understanding Evaluation) are multi-task benchmark datasets designed to assess model performance across various NLP tasks.
GLUE (General Language Understanding Evaluation)
Description: GLUE contains diverse NLP tasks like sentiment analysis, text classification, and textual entailment. These tasks rely on semi-structured text input-output pairs rather than completely free-form text.
Format: JSON/CSV with text snippets and corresponding labels.
SuperGLUE (Super General Language Understanding Evaluation)
Description: SuperGLUE introduces more complex language tasks like question answering and coreference resolution, which are also based on semi-structured text.
While GLUE and SuperGLUE are useful for benchmarking language models, it would be inaccurate to describe them solely as unstructured text datasets, since many tasks involve semi-structured input-output pairs.
Structured Data
All major enterprises today run on structured data. Structured data adheres to predefined formats, organized categories, and a fixed set of data fields, making it easier to start working with. But, beware, even structured datasets may be of poor quality, with many missing values or poor schema compliance.
Here are some examples of structured data types, links to example datasets, typical formats, and considerations relevant to each type of structured data:
Tabular Data
Example Data: Sales records, customer information, financial statements.
Considerations: When working with tabular data, consider data quality, missing values, and the choice of columns or features relevant to your analysis. You may need to preprocess data and address issues such as normalization and encoding of categorical variables.
Systems: Structured data often lives in relational database management systems (RDBMS) like MySQL, PostgreSQL, or cloud-based solutions like AWS RDS.
Graph Data
Example Data: Social networks, organizational hierarchies, knowledge graphs.
KONECT: Provides a variety of network datasets for research.
Considerations: In graph data, consider the types of nodes, edges, and their attributes. Pay attention to graph algorithms for traversing, analyzing, and extracting insights from the graph structure.
Systems: Graph data is often stored in graph databases like Neo4j, ArangoDB, or Apollo, but it can also be represented using traditional RDBMS with specific schemas for relations.
Time Series Data
Example Data: Stock prices, weather measurements, sensor data.
Considerations: Time series data requires dealing with temporal aspects, seasonality, trends, and handling irregularities. It may involve time-based feature engineering and modeling techniques, like ARIMA or other sequential models, like LSTM.
Systems: Time series data can be stored in specialized time-series databases (e.g., InfluxDB, TimescaleDB, KX) or traditional databases with timestamp columns.
Spatial Data
Example Data: Geographic information, maps, GPS coordinates.
Typical Formats: Shapefiles (SHP), GeoJSON, GPS coordinates in CSV.
Considerations: Spatial data often involves geographic analysis, mapping, and visualization. Understanding coordinate systems, geospatial libraries, and map projections is important.
Systems: Spatial data can be stored in specialized Geographic Information Systems (GIS) or in databases with spatial extensions (e.g., PostGIS for PostgreSQL).
Logs Data
Example Data: Some examples of different logs include: system event logs that monitor traffic to an application, detect issues, and record errors causing a system to crash, or user behaviour logs, which track actions a user takes on a website or when signed into a device.
Typical Formats:CLF or a custom text or binary file that contains ordered (timestamp action) pairs.
Datasets:
loghub: A large collection of different system log datasets for AI-driven log analytics.
Considerations: How long you want to save the log interactions and what you want to use them for – i.e. understanding where errors occur, defining “typical” behaviour – are key considerations for processing this data. For further details on what to track and how, see this Tracking Plan course from Segment.
Systems: There are plenty of log management tools, for example Better Stack, which has a pipeline set up for ClickHouse, allowing real-time processing, or Papertrail, which can ingest different syslogs txt log file formats from Apache, MySQL, and Ruby.
Each of these structured data types comes with its own unique challenges and characteristics. In particular, paying attention to data quality and pre-processing is important to make choices aligned with your vector retrieval system.
Keeping your retrieval stack up to date with Change Data Capture
In any data retrieval system, a key requirement is ensuring the underlying representations (i.e. vector embeddings) accurately reflect the latest state of source data. As underlying data changes – e.g., product updates, user activities, sensor readings – corresponding vector representations must also be kept current.
One approach to updating your data is batch recomputation – periodically rebuilding all vectors from scratch as the new data piles up. But batch recomputation ignores incremental changes between batches.
Change Data Capture (CDC) provides a more efficient alternative – capturing granular data changes as they occur and incrementally updating associated vectors. Using CDC, an e-commerce site, for example, can stream product catalog changes to update product vectors rapidly. Or, a real-time anomaly detection system can employ CDC to incorporate user account changes to adapt user vectors. As a result, CDC plays an integral role in keeping vectorized data aligned with changing realities.
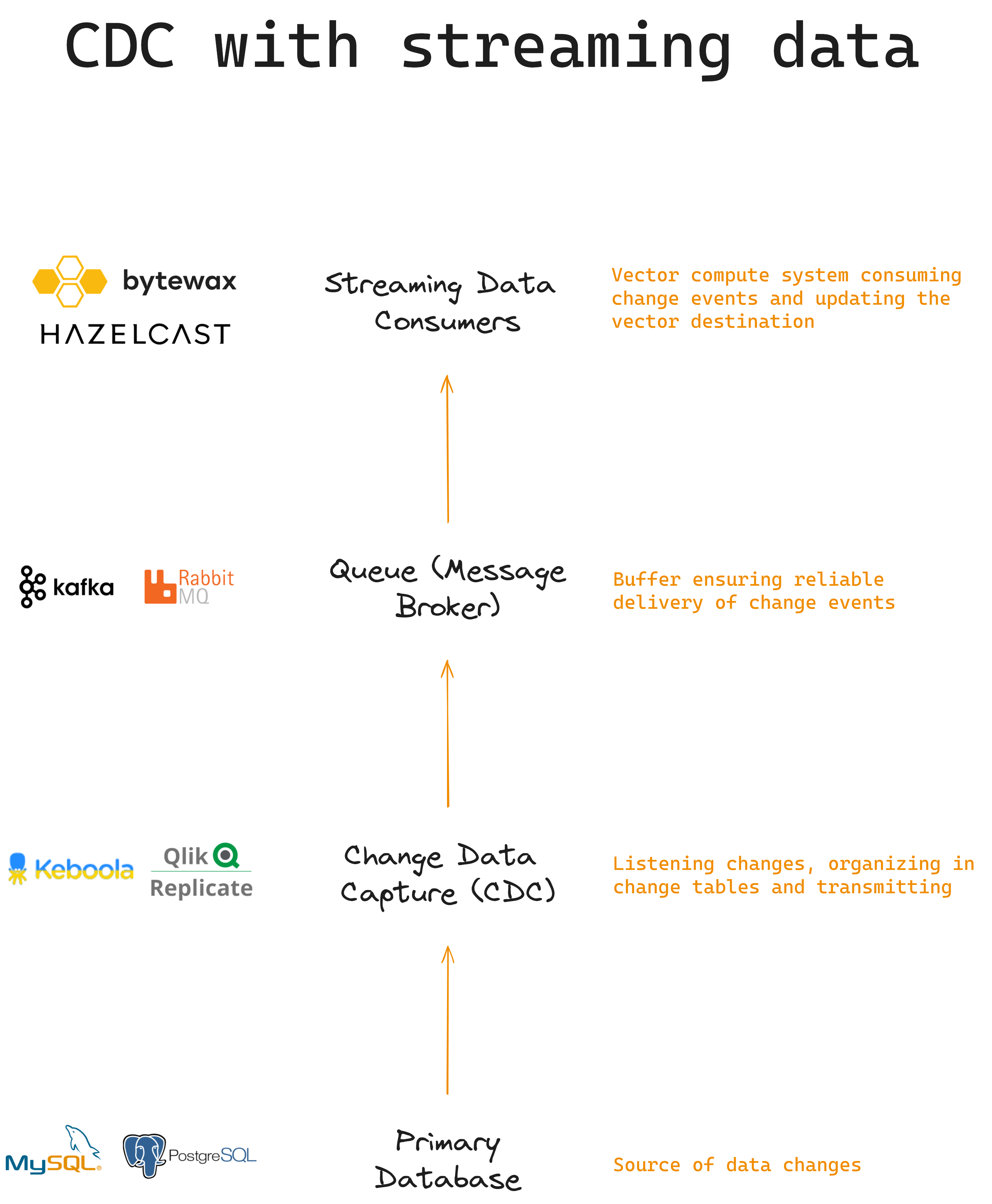
The visualization below shows how CDC can be implemented within a streaming data retrieval system. A primary database emits CDC into a queue, which is then consumed like any other streaming data source:
Primary Database:
The primary database, which can be MySQL, PostgreSQL, SQL Server, or other database management system, serves as the source of data changes.
It continuously captures changes to its tables, including inserts, updates, and deletes, in its transaction logs.
Change Data Capture (CDC):
CDC technology, for example Kebola or Qlik Replicate, acts as the bridge between the primary database and your retrieval system, detecting and managing incremental changes at the data source.
A dedicated capture process is responsible for reading these changes from the transaction log of the primary database.
These changes are then organized and placed into corresponding change tables within the CDC system.
These change tables store metadata about what data has changed and when those changes occurred.
Queue (Message Broker):
The CDC system efficiently transmits these organized changes into a message queue, which can be implemented using technologies like Apache Kafka or RabbitMQ.
The message queue acts as a buffer and is crucial in ensuring the reliable delivery of change events to downstream consumers.
Streaming Data Consumers:
Applications, analytics pipelines, and other data consumers subscribe to the message queue.
Streaming data consumers actively consume change events in real-time, just as they would with any other streaming data source.
These consumers treat CDC data as a continuous flow of real-time data, making it readily available for processing and analysis.